

Starting an article based on so old concept of technology can be a simple task, but i just realize how much the new IT generation as not been trained or educated to this basics.
I remember a discussion 15 years ago with a CEO of a well known French bank, in a simple world the discussion finish “don’t dream there is standard Francois, we rely on others experience and standards” end of story.
That’s why conceptually as human we are doing what others are doing.
Back on my subject high availability, where does it come from ?
Who’s remember 9/11 ? who’s remember the speleologist payed a fortune to find some lost information in this destroyed building in this major human disaster, you can here evaluate the value of your data.
Have you personally experience a faulty IT system, a bad restore, a broken process that doesn’t give the expected result, and now have you experience a cyber ATTACK in your enterprise ?
Question: have you done the job related to the needed investment to maintain your production in a real high standard compliant, workable, sustainable environment, yes now we are introducing the concept of High Availability and Disaster Recovery
Do you think that your data are “magics” ?

What’s was your day yesterday ? we came from virtualization world, containerization, now Cloud FaaS (microservices), Infrastructure as Code, etc…
What is you SLA SLO ? have you really evaluate which risk you are taking or not, by the way who care about you and your data ?
So the question is did systems failure will happen ?
Oooooh yes of course and systems failure will happened and happen and will always happen and forever.
Proven record is the number of event that happen in a DataCenters, for example the last well known datacenter disaster where client lost their data having no backup or recovery solution, you want the real answer about this technology choice ? (ask me).
3.6 million websites taken offline after fire at OVH datacenters
If we have spend decades of technology development for that a cost cuter decided to run a vital workload in a non warranty non restorable non understandable environment, that’s the first disaster.
If paying an IT professional decision maker is too expensive for you, try an amateur one it will cost you much much more.
Let’s start with very a very old concept “the responsibility” or in our digital world the RACI Matrix about your IT.
Who is the responsible at the end of the technical value of the chosen technology in your Datacenter or in the Cloud ?
Same for you between rules and regulation, adoption of metrics and methodology there’s you as human your own responsibility to take the good decision for you and your business.
Making responsibility a company value (recognition) is the way to engage a High Avalibility and Disaster Recovery plan valuable for you and your enterprise.
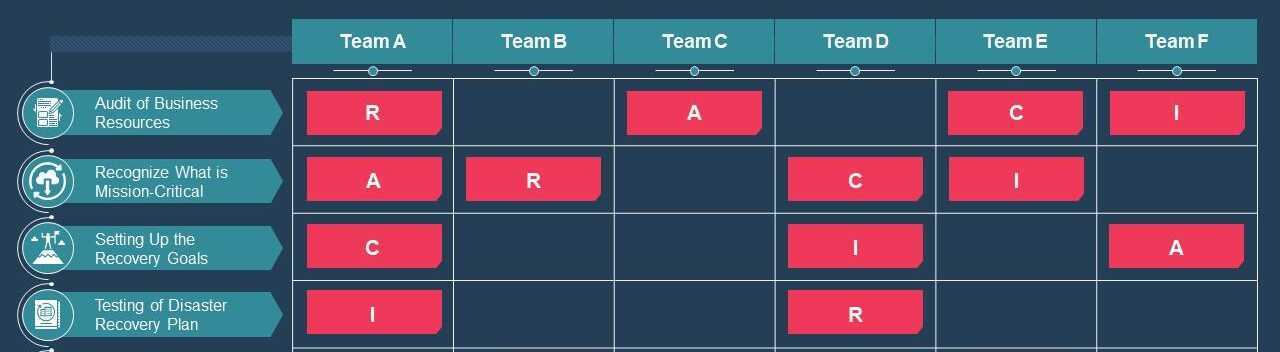
Introduce a concept of “responsibility” the “RACI Matrix”
An example of RACI Matrix for Disaster Recovery:
Goal is to Enter in a model of responsibility to establish and address a High Availability then Disaster Recovery model.
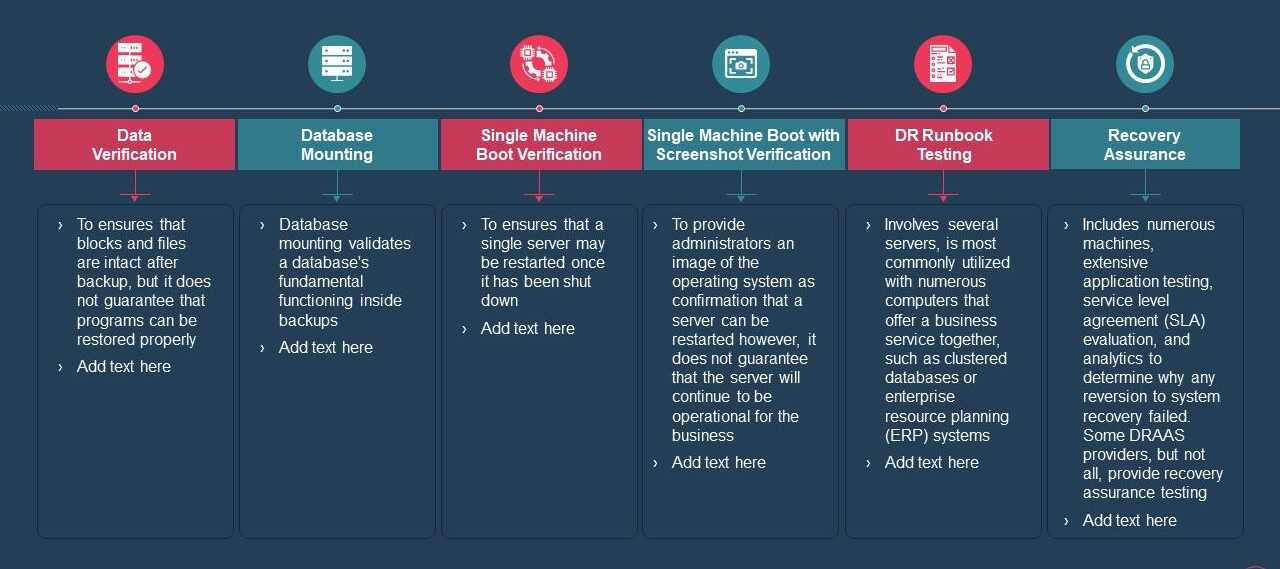
Levels of Disaster Recovery Testing
RACI Matrix Role distinction
There is a distinction between a role and individually identified people: a role is a descriptor of an associated set of tasks; may be performed by many people; and one person can perform many roles. For example, an organization may have ten people who can perform the role of project manager, although traditionally each project only has one project manager at any one time; and a person who is able to perform the role of project manager may also be able to perform the role of business analyst and tester.
- R = Responsible (also recommender)
- Those who do the work to complete the task.[7] There is at least one role with a participation type of responsible, although others can be delegated to assist in the work required. (See also RASCI below for separately identifying those who participate in a supporting role.)
- A = Accountable (also approver or final approving authority)
- The one ultimately answerable for the correct and thorough completion of the deliverable or task, the one who ensures the prerequisites of the task are met and who delegates the work to those responsible.[7] In other words, an accountable must sign off (approve) work that responsible provides. There must be only one accountable specified for each task or deliverable.[8]
- C = Consulted (sometimes consultant or counsel)
- Those whose opinions are sought, typically subject-matter experts, and with whom there is two-way communication.[7]
- I = Informed (also informee)
- Those who are kept up-to-date on progress, often only on completion of the task or deliverable, and with whom there is just one-way communication.[7]
We have now define a plan that open the door to provide a role and responsibility model and will give us the capacity to quantify the value of your data than take action to build solution.
 Pump boat trying to stop a major fire in a well known French DC.
Pump boat trying to stop a major fire in a well known French DC.
High availability will not fix your issue in case of DC destruction.
HA is present everywhere in IT Digital world, from power outlet to the ECC memory or the CPU RAS option, the network link aggregation, the file system itself include high availability features (ZFS ext3,4,ASM,CFS), the RAID is another resilience system.
Application clustering, load balacing, database business continuity, recovering solution, are minimizing downtime in systems, databases, and applications continuity is the key for maximizing continuity.
Modern organizations rely on business-critical systems, databases, and applications such as enterprise resource planning (ERP), customer relationship management (CRM), e-commerce, financial systems, and supply chain management to operate efficiently and deliver superior customer experiences.
When a system, database, or application fails, high availability protection restores operation to keep the business up and running.
Before moving to the cloud our job was to ensure that this capabilities was existing in the selected technologies, but have you ever done this verification (not again a cost cutting verification, a real one, does my services can continue to work in case of failure ?
Money is the nerf of war the cost driven element can make you taking dangerous decision and could be based on expectation of no failure, but you can be sure failure will happen.
Understand High Availability.
To understand HA imagine that you have 2 hearts one running and one ready to go well maintained and ready to start if the major part of you body encounter an issue, this is High Availability concept.
But the fact it is that you don’t have two hearts by default and without surgery your heart is by the way a SPOF ( a Single Point Of Failure of our body).
So will it be possible to list a way a building first an HA then a Disaster Recovery scenario that will had a certain level a warranty for your data ?
But where to start and how to continue this kind of articles ? N+1 redundancy , here we go !
Introducing redundancy in the discussion.
Redundancy is a form of resilience that ensures system availability in the event of component failure. Components (N) have at least one independent backup component (+1). The level of resilience is referred to as active/passive or standby as backup components do not actively participate within the system during normal operation. The level of transparency (disruption to system availability) during failover is dependent on a specific solution, though degradation to system resilience will occur during failover.[1]
It is also possible to have N+1 redundancy with active-active components, in such cases the backup component will remain active in the operation even if all other components are fully functional, however the system will be able to perform in the event that one component is faulted and recover from a single component failure.
https://en.wikipedia.org/wiki/N%2B1_redundancy
I’ve explain here in short why IT PROs hate the Cloud, and by the way if you don’t invest correctly in cloud N+1 at minimum with Disaster Recovery and Restore solution at disposal, you could experience some trouble.
Personnaly i’ve lived with this kind of management the guy in front of use was saying “we are in a deep shit oh oh oh” Hey, be sure to be a PRO !, not a excel bean counter.
Being a Pro is to use the IDC Model !
The definition of the SLA, SLO, 99% to 100% is a decision to be made , this decision will validate the technical design and solution description that will provide at the end a Bill of Material to order in a way to align the technical solution to the RTO/ RPO, SLA level expected.
Service-level agreements (SLAs) for high availability help ensure that key components of the IT infrastructure are operational and available during business hours. IDC has created an SLA model for high availability that defines five levels with the following uptime requirements:
• AL4 (Continuous Availability—System Fault Tolerance): No user interruption and a total maximum of no more than 5 minutes and 15 seconds of planned and unplanned downtime per year (99.999% or “five-nines” availability).
• AL3 (High Availability—Traditional Clustering): Minimal user interruption and a total maximum of no more than 52 minutes and 35 seconds of planned and unplanned downtime per year (99.99% or “four-nines” availability).
• AL2 (Recovery—Data Replication and Backup): Some user interruption and a total maximum of no more than 8 hours, 45 minutes, and 56 seconds of planned and unplanned downtime per year (99.9% or “three-nines” availability).
• AL1 (Reliability—Hot Swappable Components): All service stops and a total of 87 hours, 39 minutes, and 29 seconds of planned and unplanned downtime per year (99% or “two-nines” availability).
• AL0 (Unprotected Servers): All service stops, and no uptime SLAs are defined.
Your high availability requirements depend on the criticality of the overall system, the application, and numerous other factors, including:
• How critical the applications are to the business
• Whether customers notice an impact
• How often the applications run
• How many users are affected by downtime
• How quickly a database or application must fail over to the redundant system to avoid disruption
• How much data loss is tolerable
» Five nines availability is typically reserved for applications that require continuous “stateful” operation (99.999%).
» For business-critical applications four-nines availability is standard (99.99%).
» Non-critical systems and applications, you may only require two-nines availability (99%).
When determining acceptable downtime, it’s important to consider:
• Unplanned downtime (that is, hardware or software failures)
• Planned downtime for routine hardware and software maintenance
• Uptime at the application and database level
Various high availability solutions can help businesses achieve their SLA objectives for different systems, databases, and applications. Although continuous availability (AL4) may seem like the most appropriate goal for business-critical deployments, it’s important to find the right balance between cost and availability. Continuous availability can also have a negative impact on downtime required for planned maintenance as the system generally has to be taken offline when application or OS updates are applied, versus high availability, which typically allows for rolling updates.
So now, how to invest in HA and DR solution in a way that your investment will be as valuable as you business ?
Disaster recovery vs High Availability
As explain upper, high availability (HA) protects against single points of failure, while disaster recovery protects against multiple points of failure.
In cloud computing, protection against single points of failure at the physical infrastructure layer, including power, cooling, storage, networks, and physical servers, is completely abstracted into the overall architecture through availability and fault domains BUT The Data center of your Cloud infrastructure is still of course the SPOF.
High availability disaster recovery solutions that deliver zero data loss and zero downtime protection for databases and application get expensive when complex data mapping and replication technology is involved.
These solutions don’t provide ransomware protection, which is achieved via a comprehensive backup with a point-in-time recovery point objective and immutable storage.
Cost driven solutions are oftenly not the final solution, yes it cost a lot to have an HA Zero down time continuty, adding a disaster recovery solution for the most vital application and layered DB.
Disaster recovery (DR) is a critical component of modern business continuity planning, aiming to safeguard organizations against the potentially devastating impacts of unforeseen events.
Whether it be natural disasters, cyber-attacks, or other disruptions, a well-thought-out disaster recovery plan is essential for minimizing downtime and ensuring the resilience of businesses. In this article, we will delve deep into the concept of disaster recovery, exploring its key components, strategies, and best practices.
Defining Disaster Recovery
Disaster recovery refers to the set of policies, tools, and procedures implemented to recover or continue vital technology infrastructure and systems after a natural or human-induced disaster. The primary goal is to minimize downtime and data loss, allowing organizations to resume normal operations swiftly. DR is part of a broader business continuity strategy, which encompasses planning and preparations for all aspects of business operations.
Key Components of Disaster Recovery
- Risk Assessment: Conducting a comprehensive risk assessment is the first step in developing an effective disaster recovery plan. This involves identifying potential threats and vulnerabilities that could impact the organization, ranging from natural disasters like earthquakes and floods to human-made disasters such as cyber-attacks and hardware failures.
- Data Backup and Recovery: Regularly backing up critical data is fundamental to disaster recovery. Organizations should establish robust backup procedures and utilize off-site or cloud-based storage to ensure data redundancy. In the event of a disaster, quick and reliable data recovery mechanisms become crucial for minimizing data loss and maintaining business continuity.
- Infrastructure Redundancy: Establishing redundant infrastructure, both on-premises and in the cloud, is essential for minimizing single points of failure. This may involve deploying mirrored servers, geographically dispersed data centers, or utilizing cloud services to ensure that essential systems remain operational, even if one part of the infrastructure is compromised.
- Communication Plans: Effective communication is critical during a disaster. Establishing communication plans that outline how employees, stakeholders, and customers will be informed and updated during a crisis ensures transparency and helps manage expectations. This includes having alternative communication channels in case primary ones are disrupted.
- Testing and Training: Regular testing of the disaster recovery plan is vital to identify weaknesses and ensure that all components function as intended. Additionally, providing training to employees on their roles and responsibilities during a disaster helps enhance the overall effectiveness of the recovery process.
Strategies for Disaster Recovery
- Backup and Restore: Implementing regular data backups and having efficient restore mechanisms is a fundamental strategy. This ensures that in the event of data loss, the organization can quickly recover to a point before the disaster occurred.
- High Availability: High availability solutions involve designing systems with minimal downtime. This often includes redundant hardware, load balancing, and failover mechanisms to ensure continuous access to critical applications and services.
- Cloud-Based Disaster Recovery: Leveraging cloud services for disaster recovery provides flexibility and scalability. Cloud-based solutions enable organizations to replicate their data and infrastructure to remote locations, allowing for rapid recovery in the cloud if on-premises systems are compromised.
- Business Continuity Planning: Integrating disaster recovery with broader business continuity planning ensures a holistic approach to risk management. This involves considering not only the technical aspects of recovery but also the people, processes, and external dependencies that are critical for business operations.
Best Practices for Disaster Recovery
- Regularly Update the Plan: The business environment is dynamic, and so are the risks. Regularly reviewing and updating the disaster recovery plan ensures that it remains relevant and effective in the face of evolving threats and changes in the organization’s infrastructure.
- Documentation and Compliance: Thorough documentation of the disaster recovery plan, including procedures, contact information, and system configurations, is crucial. Compliance with industry regulations and standards ensures that the organization is meeting legal and regulatory requirements in its disaster recovery efforts.
- Collaboration and Communication: Disaster recovery is a collaborative effort that requires effective communication and coordination among different departments and stakeholders. Establishing clear lines of communication and defining roles and responsibilities is essential for a smooth recovery process.
- Regular Testing and Training: Regularly testing the disaster recovery plan through simulated scenarios helps identify weaknesses and areas for improvement. Training employees on their roles and responsibilities ensures that everyone is well-prepared to execute the plan when needed.
- Incident Response: Integrating disaster recovery with an incident response plan ensures a swift and coordinated response to a crisis. This involves a structured approach to identifying, managing, and mitigating the impact of incidents that could lead to a disaster.
Example of high availability, scalability, and disaster recovery with oracle database.
Conclusion
Disaster recovery is a complex and multifaceted discipline that plays a crucial role in ensuring the resilience and continuity of organizations. By understanding the key components, implementing effective strategies, and adhering to best practices, businesses can mitigate the impact of disasters and recover swiftly from unforeseen events. As technology evolves and new threats emerge, the importance of a robust and adaptive disaster recovery plan becomes increasingly evident in safeguarding the future of businesses worldwide.
To be Continued…

