

How does your production data can be protected for test, dev, security and or training ?
This question permit me to introduce the Data masking who is a technique used by the enterprise (that care about your data) to protect sensitive data by obscuring or encrypting it in some way.
All the enterprise grade or organizations complied with security controls that protect the production environement and their data when at rests in storage and when it is in business use, but how to use or share this Data for a specific development or a security test by a tiers or simply to outside this data for a Cloud performance test without divulgation of personnal information ?
That’s where Data Masking anonimization is introduced
Data masking is often used to protect sensitive information such as credit card numbers, Social Security numbers, and personal health information, and is commonly used in industries such as finance, healthcare, and government.
Data masking is also known as data scrambling and data anonymization.
By example: Data anonymization is the process of removing or obscuring personal identifying information from a dataset, making it difficult or impossible to trace the data back to a specific individual.
This can be done through techniques such as removing names, addresses, and other identifying information, or by using pseudonyms, aggregate data, or other methods to obscure the data. The goal of data anonymization is to protect the privacy of individuals while still allowing the data to be used for research, analysis, or other purposes.
The purpose of “data masking” is to create a fully functional copy that can be used in professional enivory and that does not reveal the real data, it is fake but usable data.
Data masking processes use the same data format to emulate the original data, while changing the values of sensitive information.
There is several ways or technice that can be used to modify data, character shuffling, character or word replacement, randomization, cleaning (zero) and encryption to make unreadable without keys.
Each method has its unique advantages.
However, when masking data the values must always be changed in some manner that makes reverse engineering impossible.
Here are the most common data types that require data masking:
- All personally identifiable information (PII)— all datatype that can be used to identify certain individuals. This includes information like full name,id,health security number, passport number, driver’s license number, and social security number.
- All health information (PHI)—data collected by healthcare service providers for the purpose of identifying appropriate care. This includes insurance information, demographic information, test and laboratory results, medical histories, and health conditions.
- Payment card information—the Payment Card Industry Data Security Standard (PCI DSS) requires merchants that handle credit and debit cards transactions to appropriately secure cardholder data.
- Intellectual property (IP)—data related to creations of the mind, including inventions, business plans, designs, and specifications, have high value for an organization and must be protected from unauthorized access and theft.$
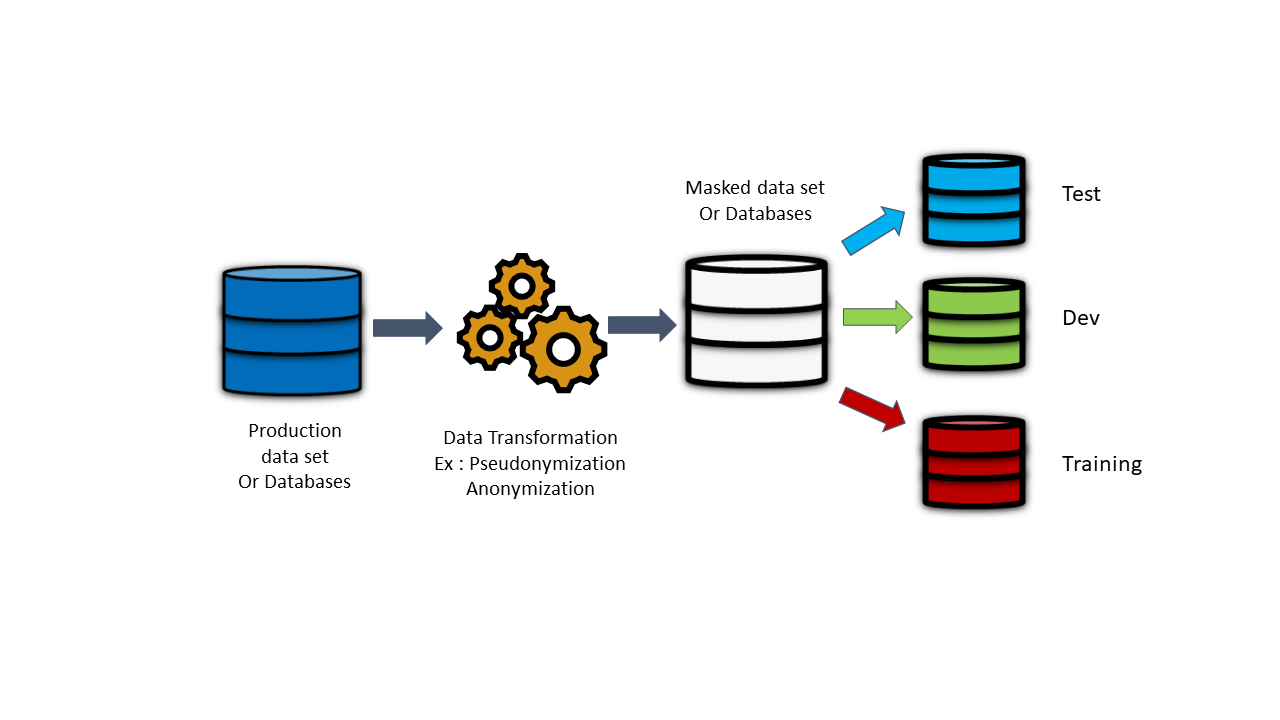
Static masking architecture looks like the below schema
You create a full-size copy of your production data or database, called The “Golden copy”or the “Mastercopy (following GDPR regulation).
On this Master copy we applied the Data masking tools that will create several new copy with modified data able to be use for different purpose like “cybersecurity test, training or development”.
Dynamic data masking
Is a real-time data masking system. It is often compared with another method for data masking, called static data masking, which involves setting up a separate shielded database or a “dummy database” including value-less data at load time.
Below A very good video by Fergus Mahon of Oracle that is explaining in detail the major concept of Data Masking and subsetting




